
Pandas 相关性分析
在 Pandas 中,数据相关性分析是通过计算不同变量之间的相关系数来了解它们之间的关系。
在 Pandas 中,数据相关性是一项重要的分析任务,它帮助我们理解数据中各个变量之间的关系。
Pandas 使用 corr() 方法计算数据集中每列之间的关系。
df.corr(method='pearson', min_periods=1)
method (可选): 字符串类型,用于指定计算相关系数的方法。默认是 'pearson',还可以选择 'kendall'(Kendall Tau 相关系数)或 'spearman'(Spearman 秩相关系数)。
min_periods (可选): 表示计算相关系数时所需的最小观测值数量。默认值是 1,即只要有至少一个非空值,就会进行计算。如果指定了
min_periods,并且在某些列中的非空值数量小于该值,则相应列的相关系数将被设为 NaN。
df.corr() 方法返回一个相关系数矩阵,矩阵的行和列对应数据框的列名,矩阵的元素是对应列之间的相关系数。
常见的相关性系数包括 Pearson 相关系数和 Spearman 秩相关系数:
- Pearson 相关系数: 即皮尔逊相关系数,用于衡量了两个变量之间的线性关系强度和方向。它的取值范围在 -1 到 1 之间,其中 -1 表示完全负相关,1 表示完全正相关,0 表示无线性相关。可以使用 corr() 方法计算数据框中各列之间的 Pearson 相关系数。
- Spearman 相关系数:即斯皮尔曼相关系数,是一种秩相关系数。用于衡量两个变量之间的单调关系,即不一定是线性关系。它通过比较变量的秩次来计算相关性。可以使用 corr(method='spearman') 方法计算数据框中各列之间的 Spearman 相关系数。
Pearson 相关系数
import pandas as pd
# 创建一个示例数据框
data = {'A': [1, 2, 3, 4, 5], 'B': [5, 4, 3, 2, 1]}
df = pd.DataFrame(data)
# 计算 Pearson 相关系数
correlation_matrix = df.corr()
print(correlation_matrix)
输出结果:
A B A 1.0 -1.0 B -1.0 1.0
说明:由于数据集是线性相关的,因此 Pearson 相关系数矩阵对角线上的值为 1,而非对角线上的值为 -1 表示完全负相关。
Spearman 秩相关系数
import pandas as pd
# 创建一个示例数据框
data = {'A': [1, 2, 3, 4, 5], 'B': [5, 4, 3, 2, 1]}
df = pd.DataFrame(data)
# 计算 Spearman 相关系数
spearman_correlation_matrix = df.corr(method='spearman')
print(spearman_correlation_matrix)
输出结果:
A B
A 1.0 -1.0
B -1.0 1.0
说明:Spearman 相关系数矩阵的结果与 Pearson 相关系数矩阵相同,因为这两个变量之间是完全的单调负相关。
可视化相关性
这里我们要使用 Python 的 Seaborn 库, Seaborn 是一个基于 Matplotlib 的数据可视化库,专注于统计图形的绘制,旨在简化数据可视化的过程。
Seaborn 提供了一些简单的高级接口,可以轻松地绘制各种统计图形,包括散点图、折线图、柱状图、热图等,而且具有良好的美学效果。
安装 Seaborn:
pip install seaborn
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 创建一个示例数据框
data = {'A': [1, 2, 3, 4, 5], 'B': [5, 4, 3, 2, 1]}
df = pd.DataFrame(data)
# 计算 Pearson 相关系数
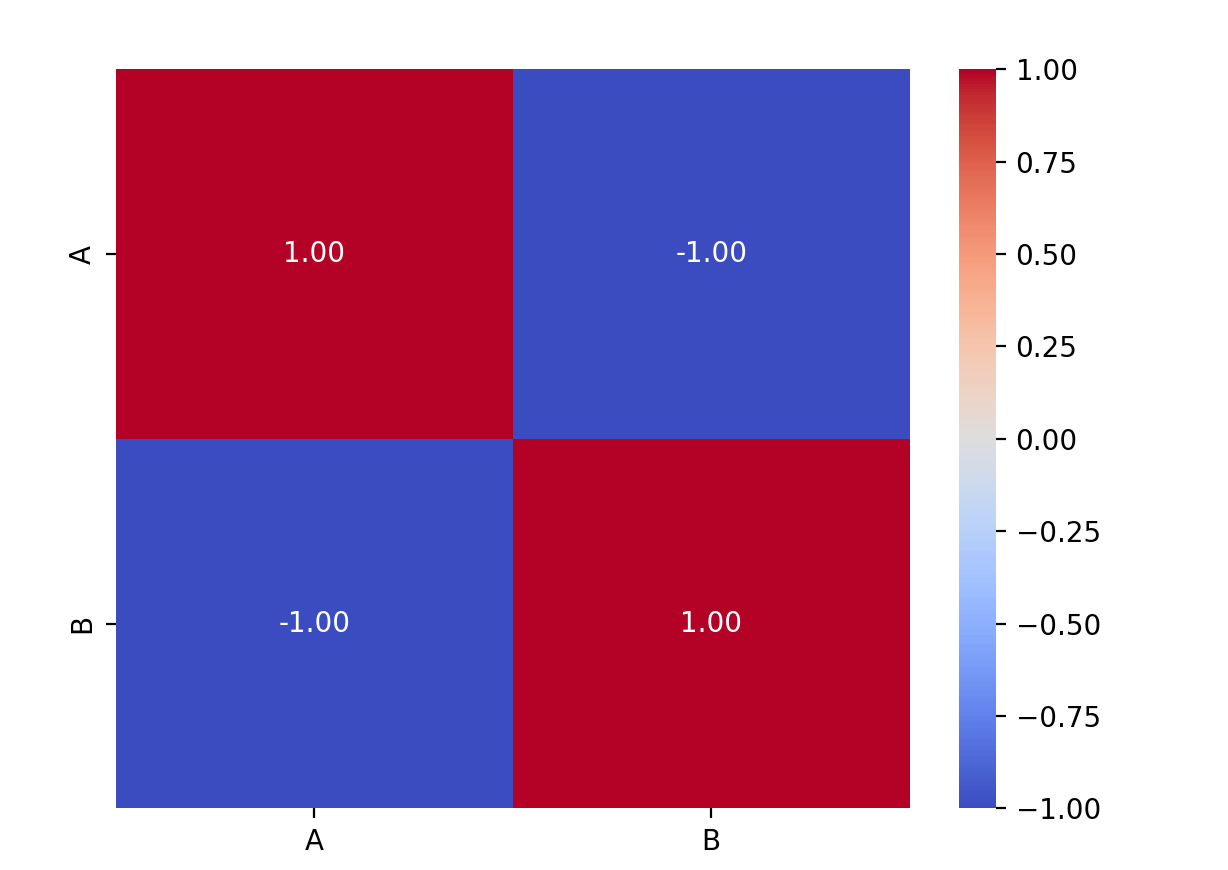
correlation_matrix = df.corr()
# 使用热图可视化 Pearson 相关系数
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.show()
说明:这段代码将生成一个热图,用颜色表示相关系数的强度,其中正相关用温暖色调表示,负相关用冷色调表示。annot=True 参数在热图上显示具体的数值。
选择相关性阈值



